Predicting Sales related to counterfeit Medicines: Using Decision Tree and Random Forest Model
Click to View Rpubs Report
Click to View Github Code and Datasets
OBJECTIVE
Click to View Github Code and Datasets
OBJECTIVE
Use RandomForest and Decision Tress to build your model of predicitng sales on train data and compare their performance on test data. Also get the variable importance plot for the model.
Use dataset "base_data.csv" to build a model.Variable names are self explanatory. Aim here is to build predictive model for predicting sales figures given other information related to counterfeit medicine selling operations.
TAGS
Decision Tree, Random Forest Model, Pruning Trees, Terminal Nodes.
PROJECT METHODOLOGY
We will first build decision tree model followed by random forest classification model: The steps followed are given below:
- Step 1: Data preparation
- Step 2. Building decision tree model on train data
- Step 3. Use the model to predict on test dataset and find error ( RMSE )
- Step 4. Prune the tree and find optimised solution.
- Step 5.Build the model using random forest method.
- Step 6.Compare and see which model performs better(i.e. gives less RMSE).
DATA DICTIONARY
- Dataset base_data.csv is given to build models. It consists of 8523 observations and 12 variables.
- Evaluation Criterion :RMSE,lower RMSE better the model.
CONCLUSION
RMSE by decision tree is 49925 and that by random forest is 49057. Hence random forest is little better model.

Decision tree with 6 terminal nodes.
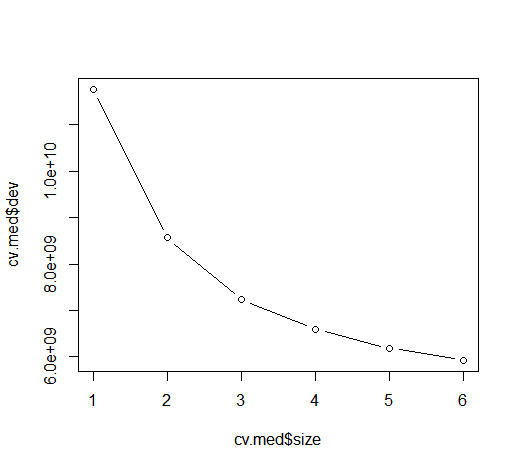
Pruned tree plot showing optimised number of nodes.
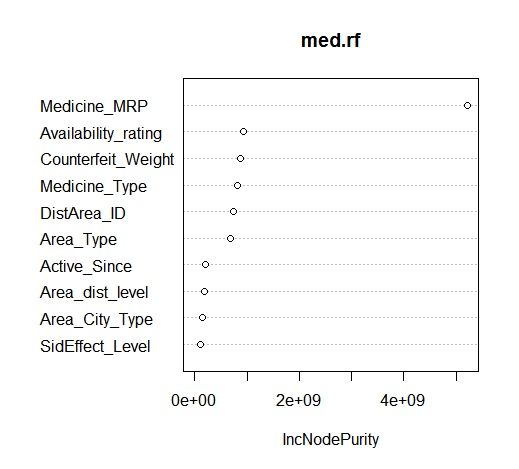
Variable Importance plot showing medicine_MRP and Availability Rating as most important variables contributing to the model.