Wine Quality Segmentation: K Means CLustering Algorithm
Click to View Rpubs Report
Click to View Github Code and Datasets
OBJECTIVE
Click to View Github Code and Datasets
OBJECTIVE
Using K-means clustering algorithm classify the wines into appropriate distinguished optimal clusters having similar properties in each cluster.
Wine quality depends on a lot of factors like alcohol content,presence of sulphates,its pH values etc. The taste,smell and potency of the wine is defined by its chemical ingredients and its percentages in wines. A restaurant needs to classify its wines into different categories depending on its ingredients and label it accordingly for its different category of customers.
TAGS
K Means Clustering, Silhouette Plots, Segmentation, Standardization and Scaling.
PROJECT METHODOLOGY
The steps followed in the project are given below:
- Step 1: Reading and standardizing dataset as per the requirements.
- Step 2. Using K mean clustering for values k=1 to 15 and determine the best value of K.
- Step 3. Use the above best value of k=5 and make 5 clusters by K means algorithm in dataset wine_std.
- Step 4. Making Pair wise profiling plots and labelling wines with respect to its ingredients proportions.
- Step 5. Plotting silhouette.
- Step 6. Numerical Inferences and Conclusion.
DATA DICTIONARY
- winequality-red.csv consists of 1599 observations of wines having 12 variables.
- Use variables pH, alcohol, sulphates and total.sulpur.dioxide to segment the dataset appropriately using k means clustering algorithm.
CONCLUSION
Clustering of red wines in accordance to its proportions of chemical ingredients is Succesfully done having 5 Clusters and average silhouette value= 0.41.
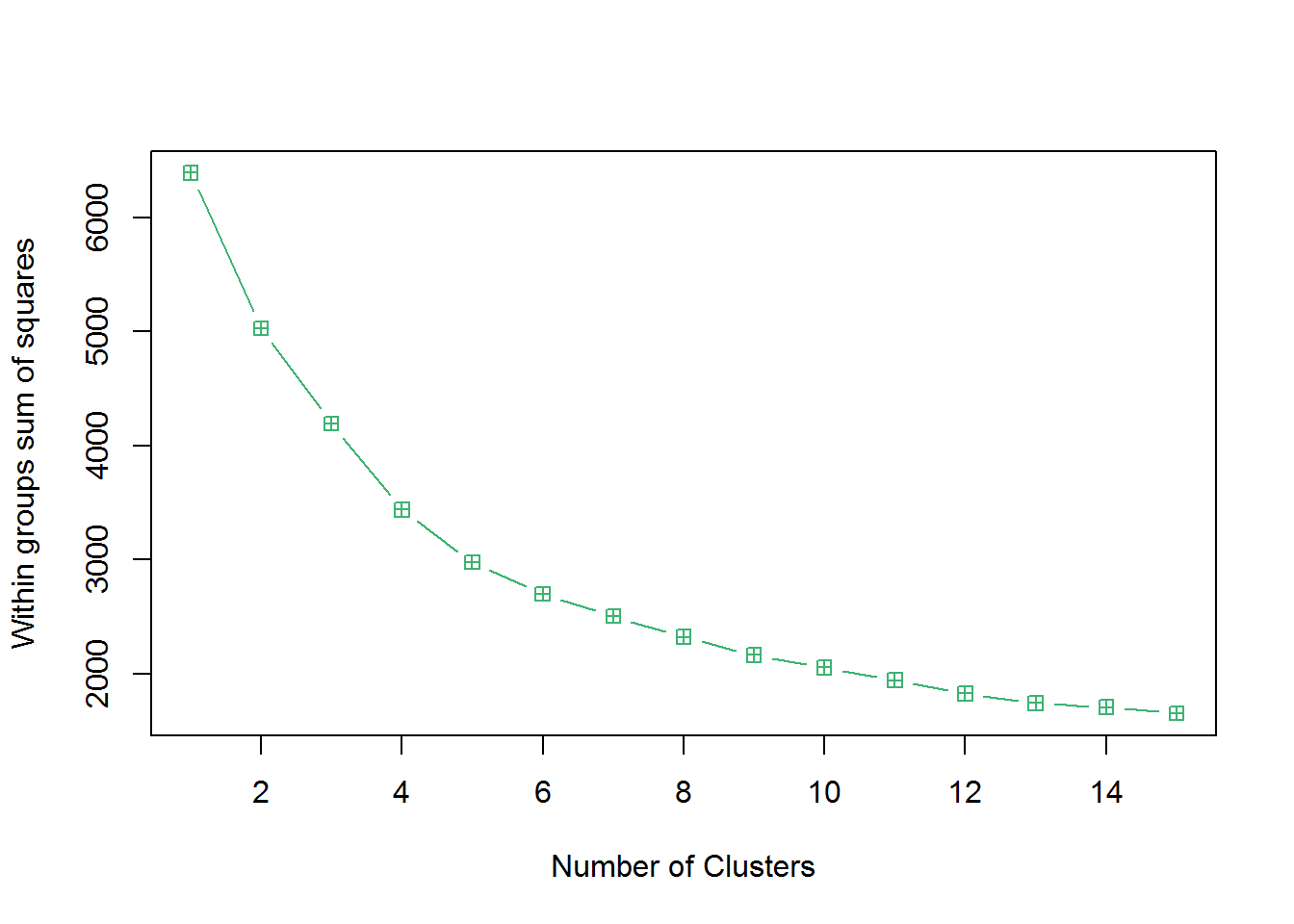
Number of Clusters Vs SSW Plot
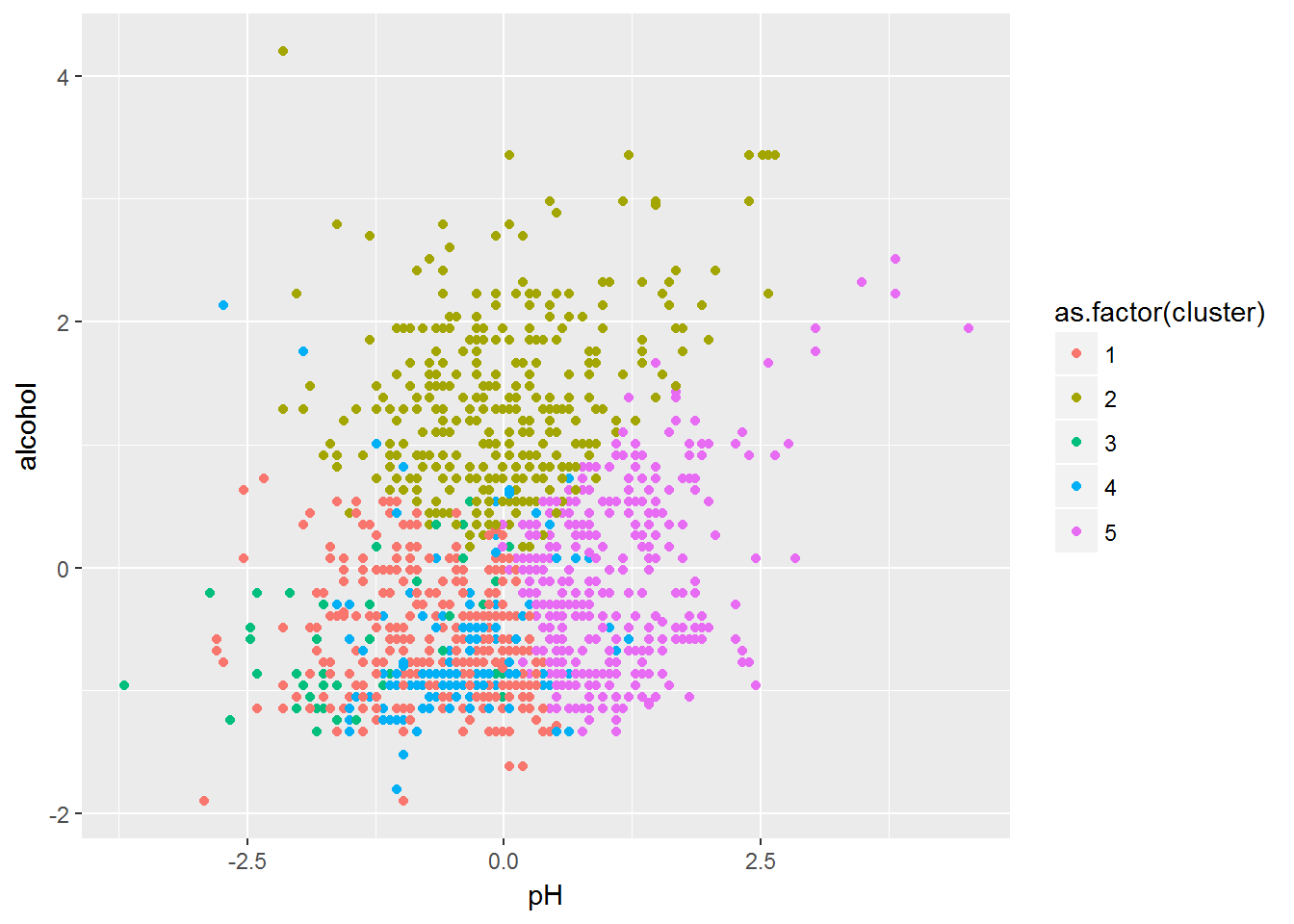
pH Vs Alcohol Clusters Plot
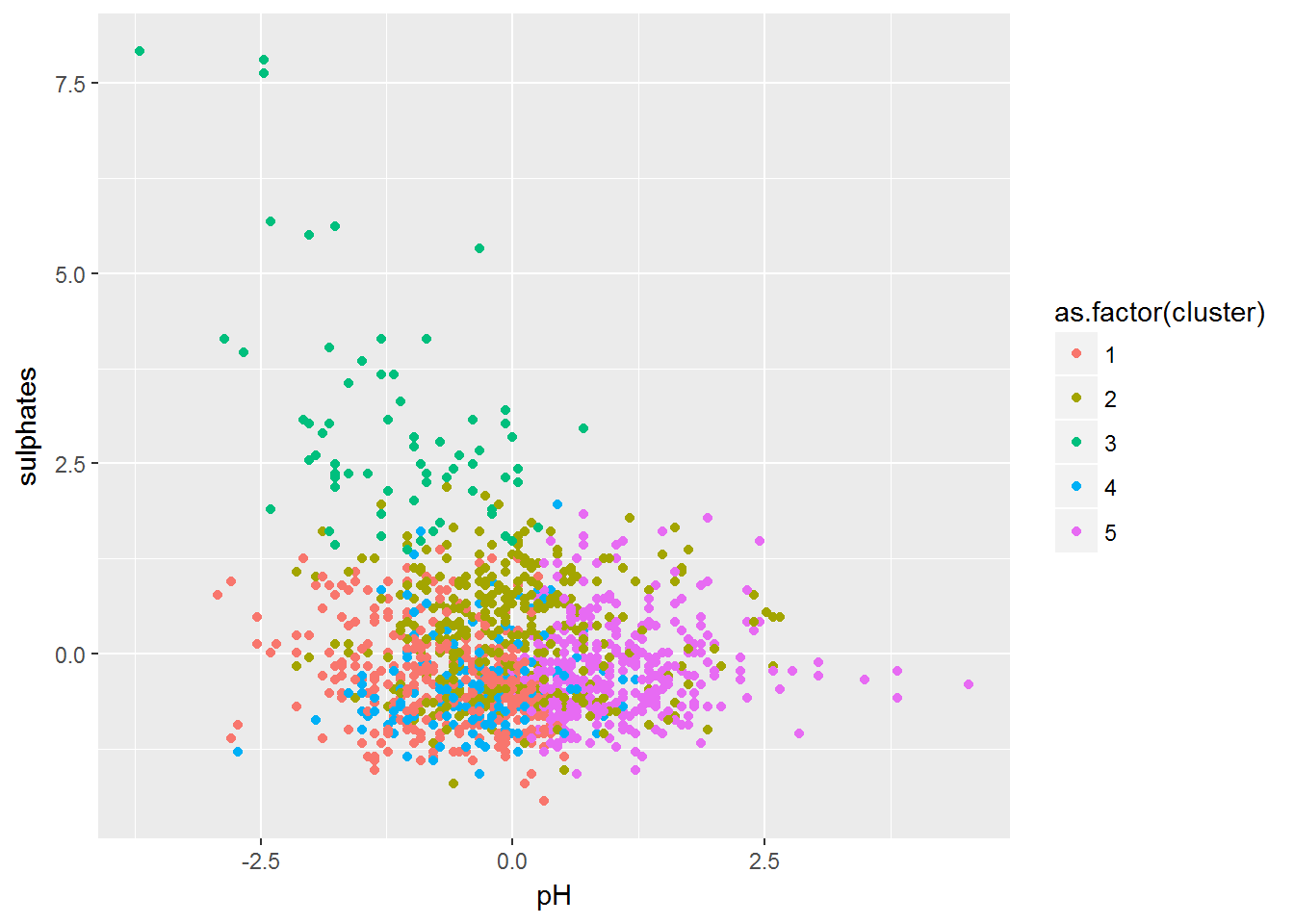
pH Vs Sulphates Clusters Plot
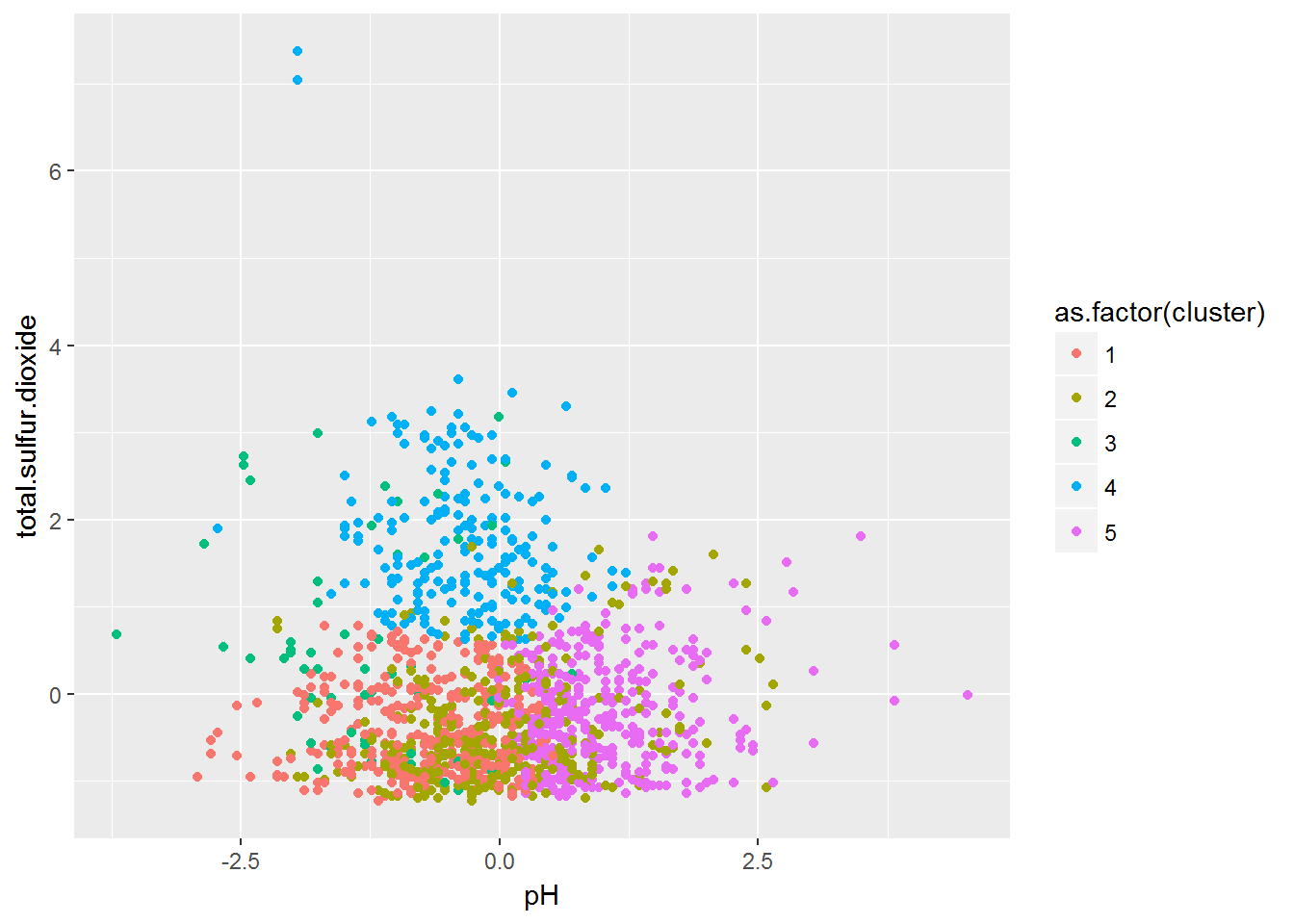
pH Vs Total.sulpur.dioxide Clusters Plot
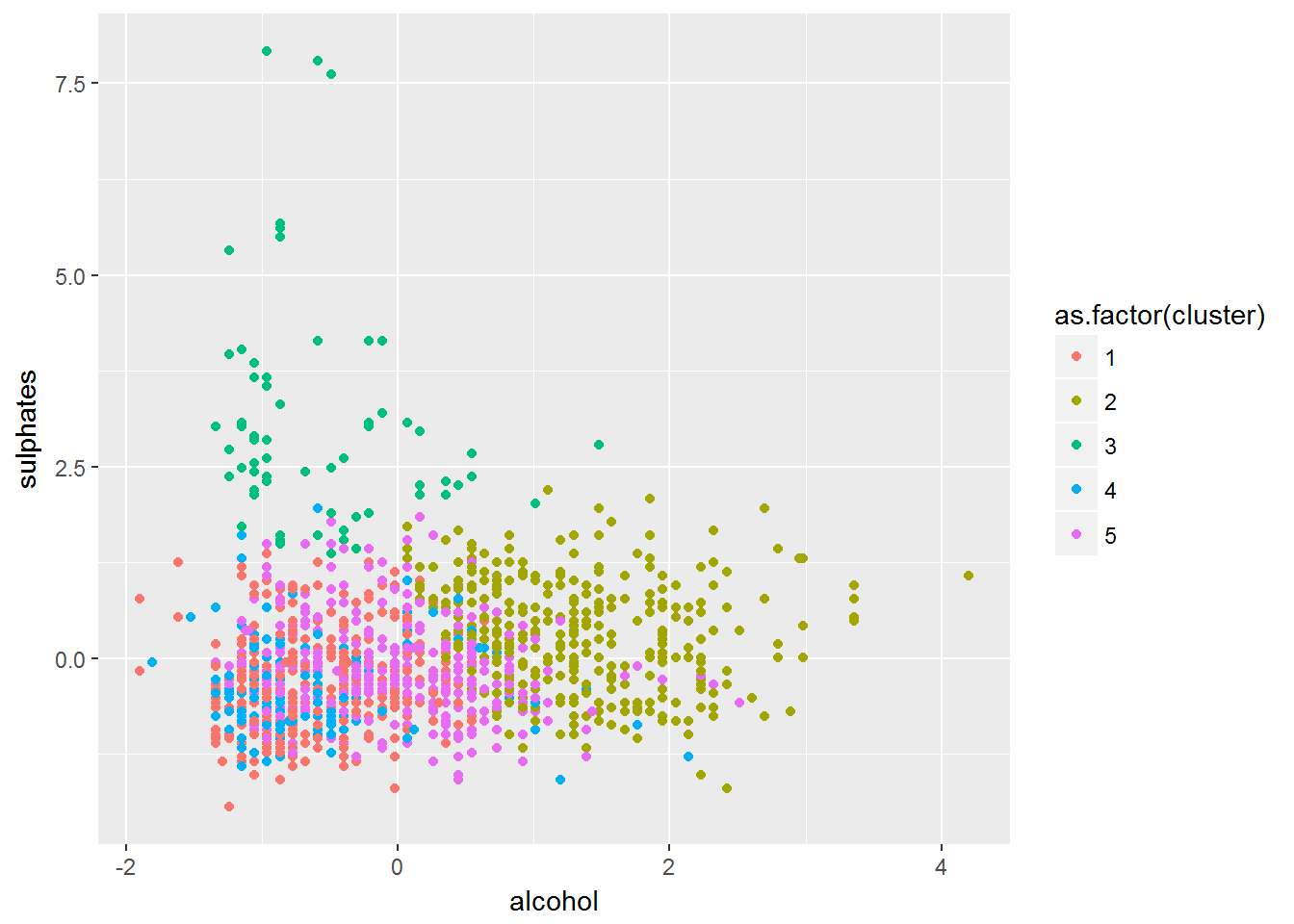
Alcohol Vs Sulphates Clusters Plot
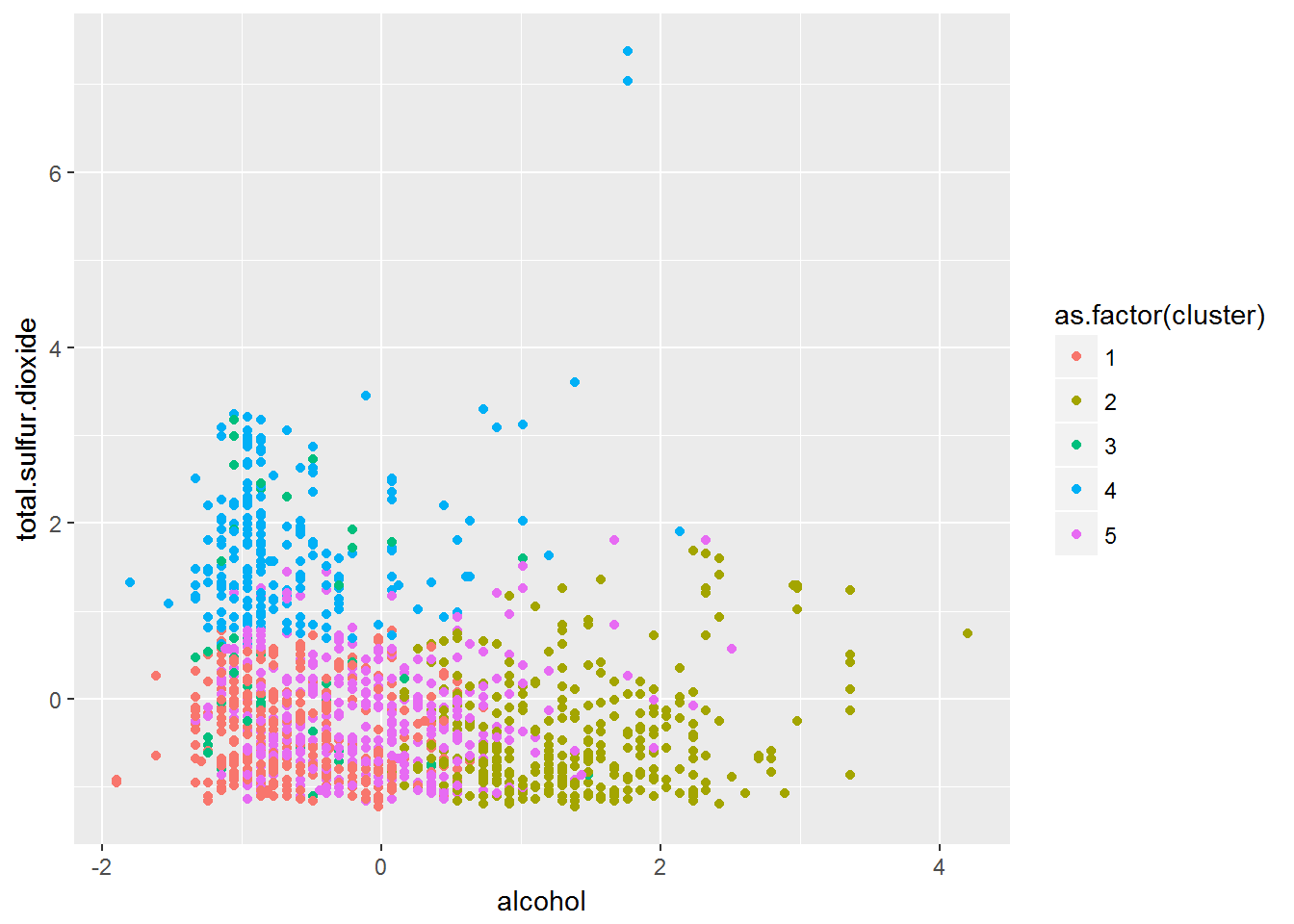
Alcohol Vs Total.sulpur.dioxide Clusters Plot
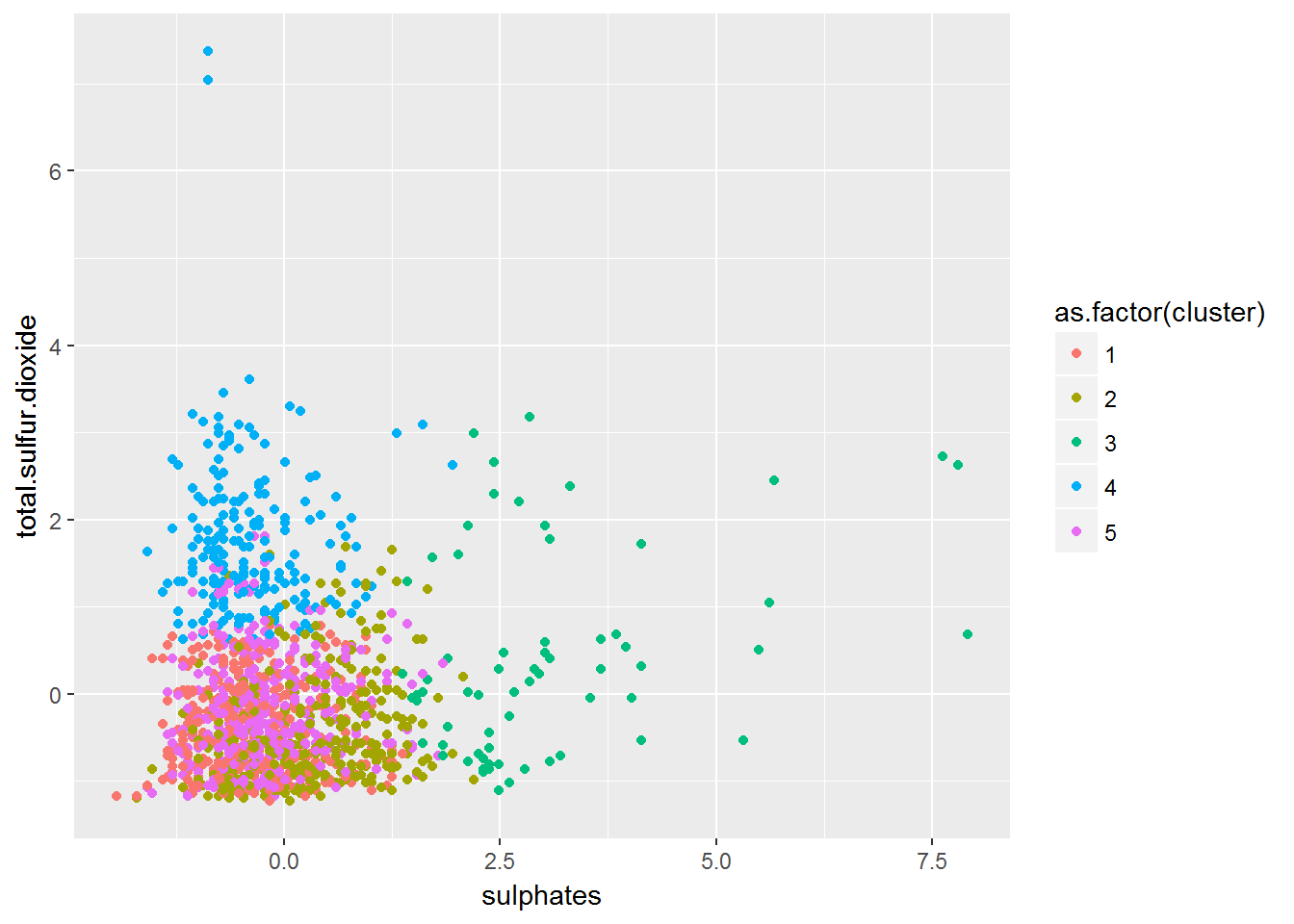
Sulphates Vs Total.sulpur.dioxide Clusters Plot